
Introduction to data structures
Concepts of data structure and algorithm, Relation between Data Structure & Algorithm, Introduction to Time & Space complexity, Types of asymptotic notations and orders of growth, Algorithm efficiency -best case, worst case, average case, Representation of Arrays.
time and space complexity
it is an approximation that we are calculating how much time and space an algorithm may take, because it solely depends on the machine hardware, if the machine is efficient then the code runs faster, otherwise even the most optimized code may lag often.
then why do we even calculate? exactly, we don’t. we take an approximation, and that is the reason we neglect the constants because they hardly affect the approximation, so the major factor of this approximation depends on the input, it is obvious that the larger the array, the more time it may take to traverse the array, and more space will be needed as well.
however, in a modern world, we have huge ram sizes, so reducing space hardly matters, what really matters is the time, because everyone wants their websites to load as fast as possible without any lags.
suppose we were searching for an item among 1 billion items, time it will take will be relative to that input size of 1 billion items, and if we traverse through that array one item after another, it will take O(1 billion).
in computer science, to be on a safe side, we focus more on the worst-case, rather than average or best case, the worst-case is shown as Big O notation, O(n) where n is input size.
suppose we have used two loops to traverse a 2d array, and if the element was not found, then it will take least O(n^2) time to fully traverse the array, so whatever the input size is, the time will be square of that relative size, and to be on a safer side, Big O notation says, it cannot be more than square of n.
in computer science, the best-case is often notated as Big Omega Notation (Ω),
and the average-case is often notated as Big Theta notation Θ().
suppose in the same 2d array, the element to be found came out to be the first element, then the loop is terminated, and somehow, the best-case turned out to be a constant, irrespective of the input size, in special cases like these, Ω notation is used, here Ω(1).
and suppose in the same 2d array, the element to be found is somewhere in the middle, and once found, the loop is terminated, then the average-case can be half of the worst case, Θ( (n^2)/2 ), and because the divider is a constant, and hardly affects half of the 2d array traversal, it is still Θ(n^2) for average case.
theoretically, there are 5 notations, the other two being small theta ω() and small omega o(), which is not much used, and only has some significance in algorithmic maths.
for coding part, we’d not go in much detail, only the Big O notation will be used,
because the worst-case analysis keeps us at a safer side.
Big O notation
to quickly analyze time complexity, generally if there are no loops involved, it’d be O(constant), because all lines of code are independent of any inputs involved, and even if there’d be any inputs, if they are defined set of inputs, such as a size already defined in the code, then it is also constant, because when you have the size as a value, its approximation does not makes much sense, its only when the actual size is not known, then approximation is much needed.
O(1) time
#include <stdio.h>
intmain(){
int i, e = 1, f = 2;
scanf("%d", &i);
int arr[2];
printf("constants are used, O(1)");
return0;
}
now, if there is a loop, and that loop manipulates on some input size that is not determined at compile-time, but depend on user-input at run-time, then the Big O notation will be O(input),
O(n) time
#include <stdio.h>
intmain(){
int n;
scanf("%d", &n);
int arr[n];
for(int i = 0; i < n; i++){
arr[i] = i;
printf(" %d ", arr[i]);
}
return0;
}
for the input size user gives, the code will run accordingly, that means time taken for the array to traverse the loop completely is directly proportional to the input size given by the user, hence the complexity is O(n).
time complexity practice
#include <stdio.h>
int main(){
int n, m;
scanf("%d %d", &n, &m);
int arr_one[n];
int arr_two[m];
for(int i = 0; i < n; i++){
arr_one[i] = i;
printf(" %d ", arr_one[i]);
}
printf("\n");
for(int i = 0; i < m; i++){
arr_two[i] = i;
printf(" %d ", arr_two[i]);
}
return 0;
}
O(n + m)
what’s happening above, is that we are taking two inputs from user, now, it is neither O(n) nor O(m), but O(n + m), because time taken will depend on both n and m input size variables.
#include <stdio.h>
intmain(){
int n;
scanf("%d", &n);
int arr[n][n];
for(int i = 0; i < n; i++){
for(int e = 0; e < n; e++){
arr[i][e] = i + e;
printf(" %d ", arr[i][e]);
}
printf("\n");
}
for(int i = 0; i < n; i++){
printf(" %d ", arr[i][i]);
}
return0;
}
5
01234
12345
23456
34567
45678
02468
O(n * n + n) = O(n^2)
here we find a nested loop, both depending on input n, but notice we have a linear loop at the end, also depending on input n, however, we neglect the lower degrees of same input variable, because the higer degree quadratic order will have a number so large enough, that a linear degree will not have any significance. remember, we take approximation of the highest degree.
#include <stdio.h>
int main(){
int n;
scanf("%d", &n);
int arr[n];
for(int i = 1; i <= n; i *= 2){
arr[i] = i;
printf(" %d ", arr[i]);
}
printf("\n");
for(int i = 1; i <= 10; i++){
printf(" %d ", arr[i]);
}
return 0;
}
10
1248
123276548500832765-1688739354
O(log n)
see here, the first loop is logarithmically growing with a base 2 as standard, even though it has skipped half of the memory blocks, the traversal at the worst-case is O(log n), because as you can see, i have given a constant to the second loop iterating till 10, so it is neglected, however, if it was size n, then time taken would be O(log n + n) = O(n), where log n is neglected, because it has a lower degree order than n.
#include <stdio.h>
intmain(){
int n;
scanf("%d", &n);
int arr[n];
for(int i = 0; i <= n; i++){
arr[i] = i;
printf(" %d ", arr[i]);
for(int e = 1; e < n; e *= 2){
printf(" %d ", e);
}
printf("\n");
}
return0;
}
5
0124
1124
2124
3124
4124
5124
O(n log n)
this is very interesting, because we’re not neglecting lower degree order, the reason is that the loops are nested, which means the growth of time depends on both, in such cases, both are in multiplication, and not in addition, so we do not neglect lower order degree when loops are nested, and order comes in multiplication, because we can clearly see that the inner loop will run n times the outer loop.
#include <stdio.h>
int factorial(int n){
if(n == 0 || n == 1){
return 1;
}
return n * factorial(n-1);
}
// 5 * 4 * 3 * 2 * 1 = 120
int fabonacci(int m){
if(m == 0){
return 0;
} else if(m == 1){
return 1;
}
return fabonacci(m-1) + fabonacci(m-2);
}
// 0 1 1 2 3 5 8 13 21 34 55
int main(){
int n, m;
scanf("%d %d", &n, &m);
printf("%d ", factorial(n));
printf("%d ", fabonacci(m));
return 0;
}
510
12055
O(n + 2^m) = O(2^m)
this program, does not involve any loops or arrays, but recursive calls that grows relative to the input size given, factorial is growing linearly on the call stack, but fibonacci is growing exponentially on the call stack, so ignoring the lower order degree, O(2^m) is the answer,
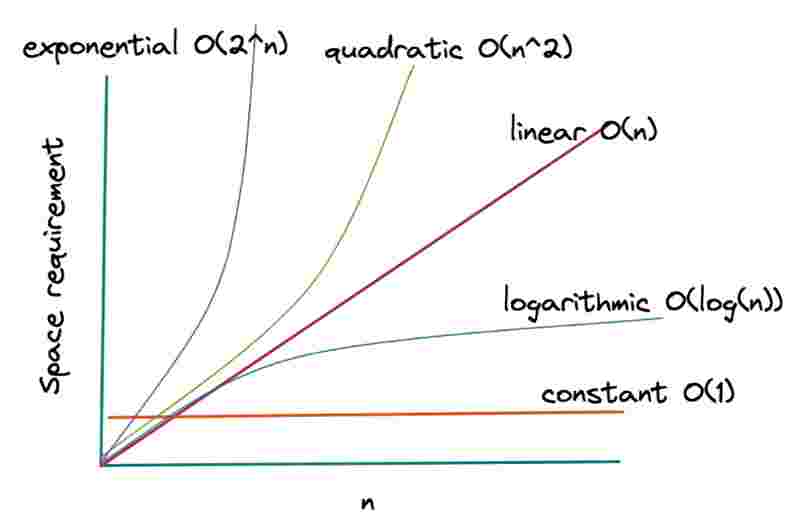
to solve a problem, it is a good practice to began with a brute force approach, and then slowly move towards a better approach, and finally towards the optimized approach, this is how we should think for a problem, the reason being that the focus should be on getting a solution on your own, which is easier when not considering to reduce time complexity in the first try, we can use as many loops as we can, and most often your solutions will be in O(n^2) or greater than that, which is really not a good time complexity, then an optimal approach can be thought of to reduce it to O(n) or lower than that, like O(n log n), O(log n), which are really good time complexities, remember that the journey from brute force to optimal solutions will take months to master, that is the reason we are learning data structures, to build our algorithmic thinking.
time complexities have a much greater significance for searching and sorting algorithms, through which we can intelligently determine which one to prefer, for example, linear search takes O(n) time, but binary search takes O(log n) time, and for sorting, bubble sort takes O(n^2) time, but merge sort takes O(n log n) time, and we’d always prefer one with lower time.
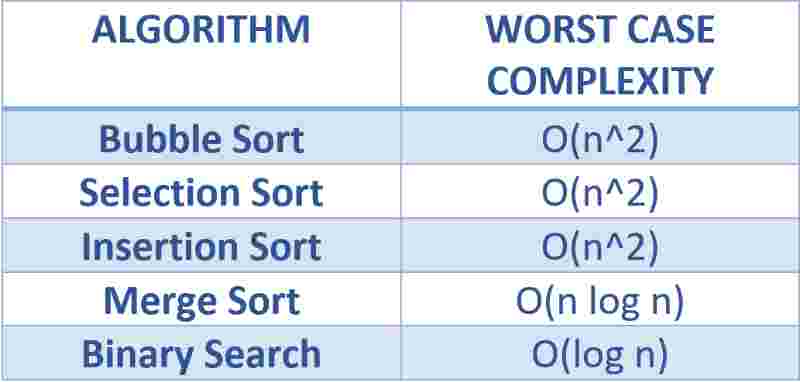
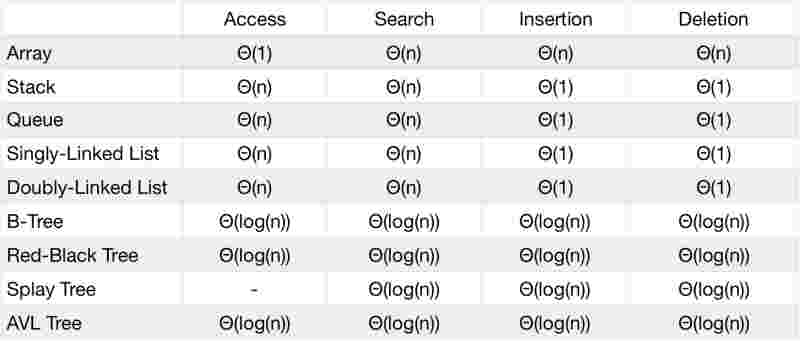
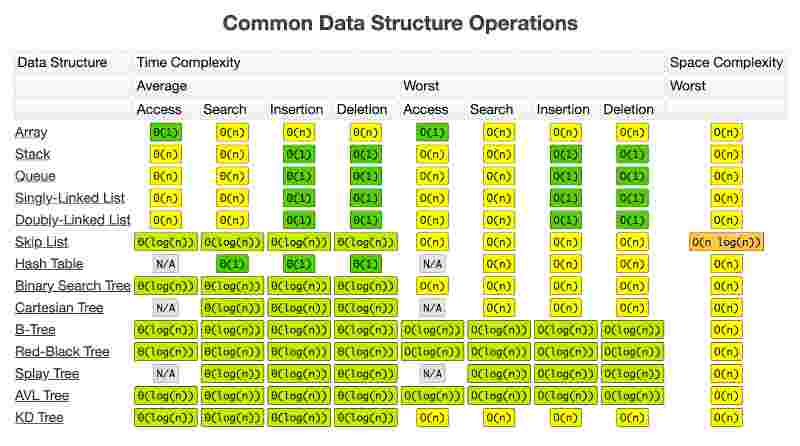
lets look at time complexity of various data structures
💬 Comments will load when you scroll here