
System Design Basics
We don't know many terms such as load balancers, dns and that becomes difficult to learn each and everything. Let's handle the basics first, and make it super easy.
SINGLE SERVER SETUP
First, we'll build a single server and a single user relaton. And then we'll scale it up, from single user to billions of user.
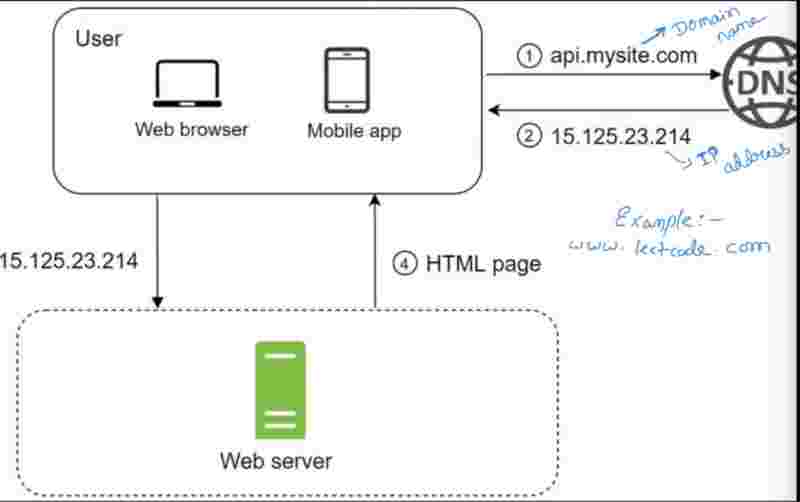
To understand this, we've to understand what domain name and ip address means.
Domain name is just your website name in english, which is easy to remember, but servers doesn't understand this, it needs a IP address..
The domain name we have is converted to IP address for the server. So, who does the conversion? DNS (Domain Name System).
So, the first step is request goes from client side to DNS, and dns gives back the IP address, and then from the IP address, we send the request to the web server, and then the website sends the response page as html.
Let us understand Traffic. Suppose, we're at a restaurent, and there is chair only for one customer. But the traffic soon becomes high as the restaurent goes popular, and more customers start coming up.
So, traffic is number of requests coming up, and requesting a server. But where does the traffic comes from?
Web applications, and mobile applications.
Web apps have two sides of a coin, server side languages and client side languages.
Mobile apps talk through http protocols with server using api response through json format.
Json is a simple key value stored format. For example,
GET /user/
{
"Name" : "Iron Man"
"Movie" : "Infinity War"
"Age" : "50"
}
But for the growth of users, our 1 server is not enoguh. We really need more servers. For millions of users, we need servers.
So, how do we scale them up our servers? How do we design it in that way efficiently so that it could handle more requests easily?
DATABASE AND MULTIPLE SERVERS
So, we were using the same server for the database handling and the traffic as well. But now, we'll have a separate server for traffic, and a separate server for database.
What happens that we can independently, scale both easily.
So, we can easily handle it, by having the web server handle the requests to the database, sending read/write requests, and returning back the data to send back to the user.
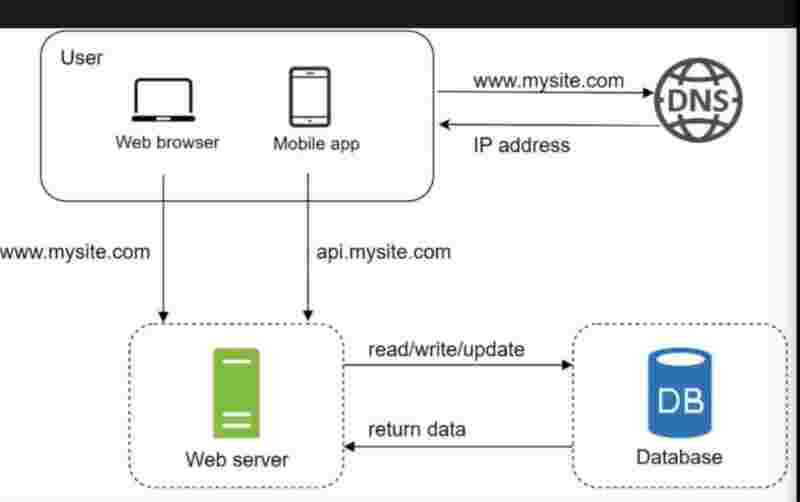
As we know, now, that we can scale the servers separately, as our web server and database has been independent now.
And as we also know now, that the load on one server has been reduced by sharing it with the database server.
What's next?
There are so many services today, and every service uses their own database to scale as per their needs.
So, which database to use? And why?
For scaling up, what does it actually mean? What are the types of scaling? Horizontal Scaling. Vertical Scaling.
WHICH DATABASE TO USE?
First, let us see how many types of databases do we have?
So, we have two types of databases.
1. Relational databases
2. Non-relational databases
Let's understand the difference between them;
Relational database is actually a RDBMS ( Relational database management system ) also SQL database. For example, MySQL, OracleDB, PostGreSQL. It is represented and stored as tables and rows. As we have tables, we can perform JOIN operations using SQL on different tables.
Non-relational databases are actually called NoSQL databases. For example, Cassandra, Amazon DynamoDB. The NoSQL databases can be grouped into 4 categories: Graph stores, Key-value stores, Column stores, Document stores. And since NoSQL databases have no such thing as a table, therefore, JOIN operations are not supported in them.
Now, the question is which one to use actually?
Well, for most developers - Relational DB. Because for the last 40 years, only relational database has been used, and it has worked really well.
But, there are many cases in which Relaitonal DB is not suitable. So, when to think about non-relatioanl DB?
1. When your application requires super low latency and quick responses.
2. When your data is unstructured and no need of defining schema like column name and type.
3. You only need to serialize and deserialize data ( JSON, XML, YAML etc )
4. When you need to store MASSIVE amount of data.
NoSQL databases have a speciality that they are boundless and restriction free. They are often used when a large quantity of complex and diverse data are needed to be organized.
So, when having millions of users storing the user information, their profile and identity, a database is necessary to be handled along with our server.
TYPES OF SCALING
So, suppose your service has become very popular and is being used by millions of users. So, it's obvious that inorder to handle such large users, you need to have that capacity and utility in your server. So, when server reaches it's maximum capability, we've to scale up.
We can scale vertically, or we can scale horizontally.
What do they actually mean?
Vertical scaling is also known as ''scale up". It means that you are adding more power to your servers that are already existing with you. Maybe by adding cpu or maybe by adding more ram.
Horizontal scaling is also known as "scale out" which means adding more servers rather than increasing the power of just one server. It's like replicating the same server again and again and distributing the load.
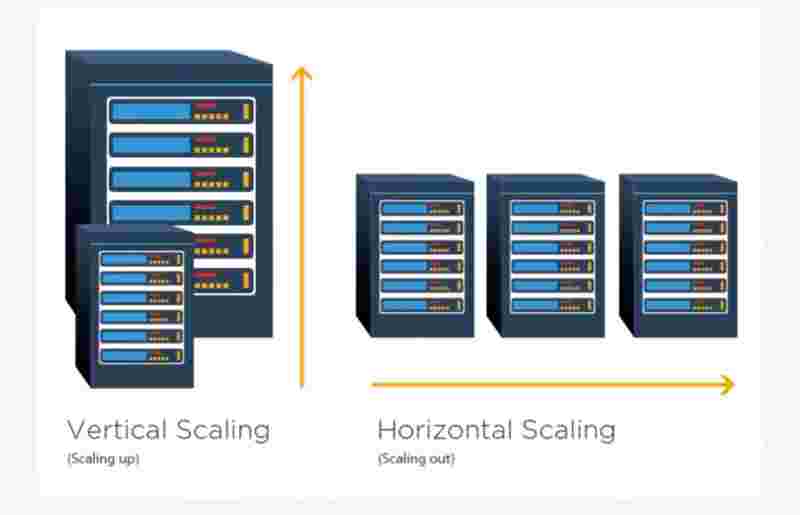
So, when to use vertical and horizontal scaling?
Vertical scaling is only feasible when traffic is low, and simplicity is its advantage. Because when traffic has become very huge, then you cannot always just push limits of one server by increasing it's power, it's limited. But because you have just one server, and you're scaling up just one server, it's really simple and easy to use.
Horizontal scaling is used for really large scale applications, and to handle a really huge traffic.
There are limitations of vertical scaling;
1. Impossible to add unlimited cpu and ram to a single server.
2. No backup (failover). If one server goes down. The website/service goes down completely.
That's why, for large scale applications, horizontal scaling is preferred due to limitations of vertical scaling.
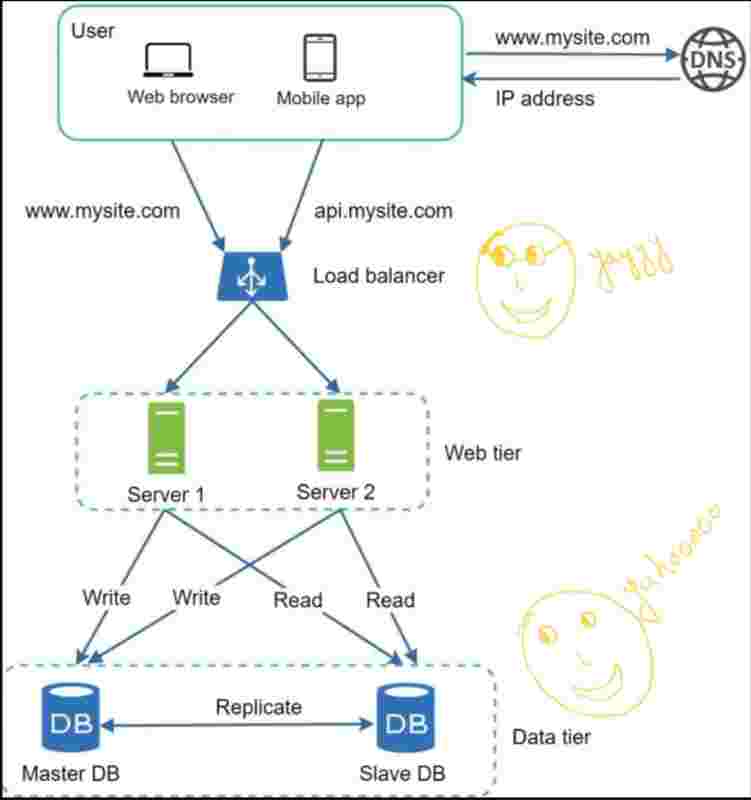
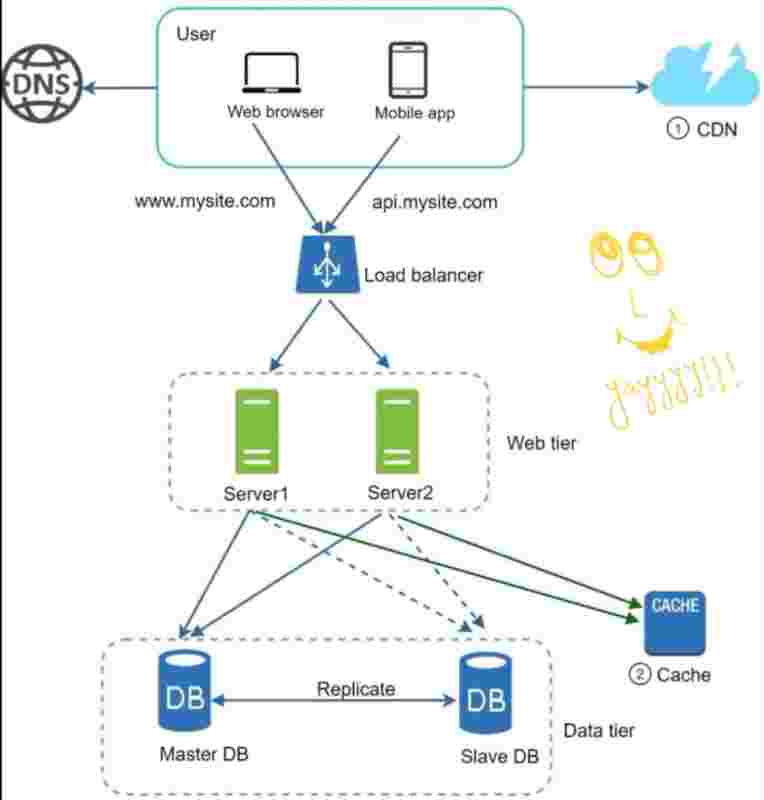
LOAD BALANCERS
So, suppose we have done horizontal scaling. But you might have noticed that the users are directly connected to the server. But what's the problem with that?
Suppose our server gets offline. Then it's a real problem, because users are directly connected. So, our service gets down.
And there can be other issues as well. Suppose a lot of users are connecting to the web server simultaneously at the same time. Then we can have other issues like, web server load limit, slow responses, or just failing to connect.
So, the best way to handle such problems is to use load balancer.
So, what does a load balancer do?
It evenly distributes web traffic.
Users are connected to the load balancer.
So, because users are connected to the load balancer, so it'll have a public ip address, and our web servers will have their private up address.
So, essentially load balancer communicates with web servers via private ip addresses.
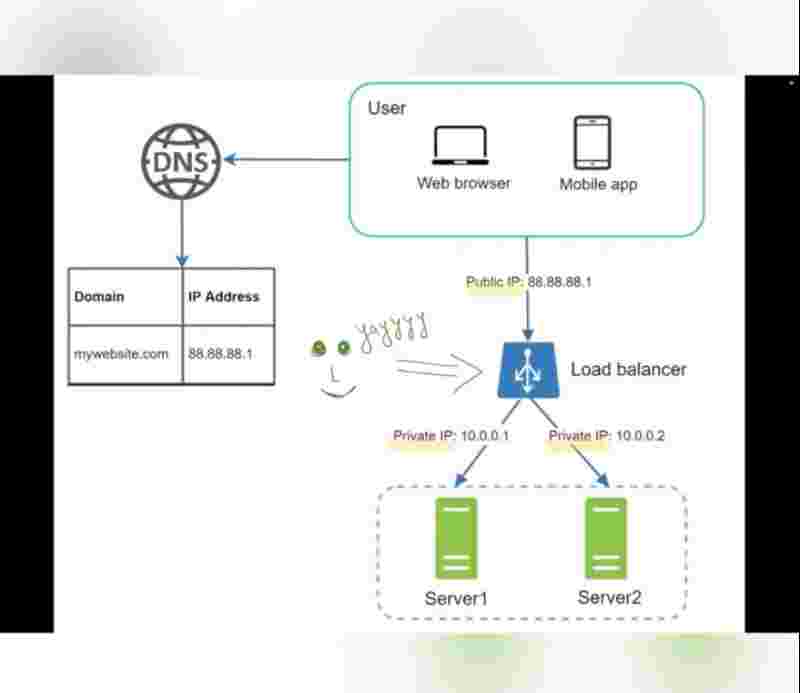
So, we have added our database, done some horizontal balancing, and added a load balancer, and we're good to go.
So, there is no failover and improved availability.
If server 1 goes offline, server 2 will get all traffic. So, our service won't go offline. We'll add new healthy web servers and balance the load.
But if website grows rapidly, 2 servers are not enough to handle traffic. Then, we just add one more server, and load balancer automatically starts to send requests to them.
What's next?
Our database is still one. If database goes down, then what? When database server fails?
DATABASE REPLICATION
As the name suggests, we make the copy of the database, which has to be handled by us. So, we have a master and a slave. The original database is said to be the master db and the replicas are said to be slaves.
Master only handles the write operations, all the insert, delete, update data modifying commands. Slaves are used for read operations. It gets copies of data from master.
So, all the updates in master db are automatically being updated in all the slave databases as well. It's obvious that we don't want our slave to be out of date. We'd want it to be same for both.
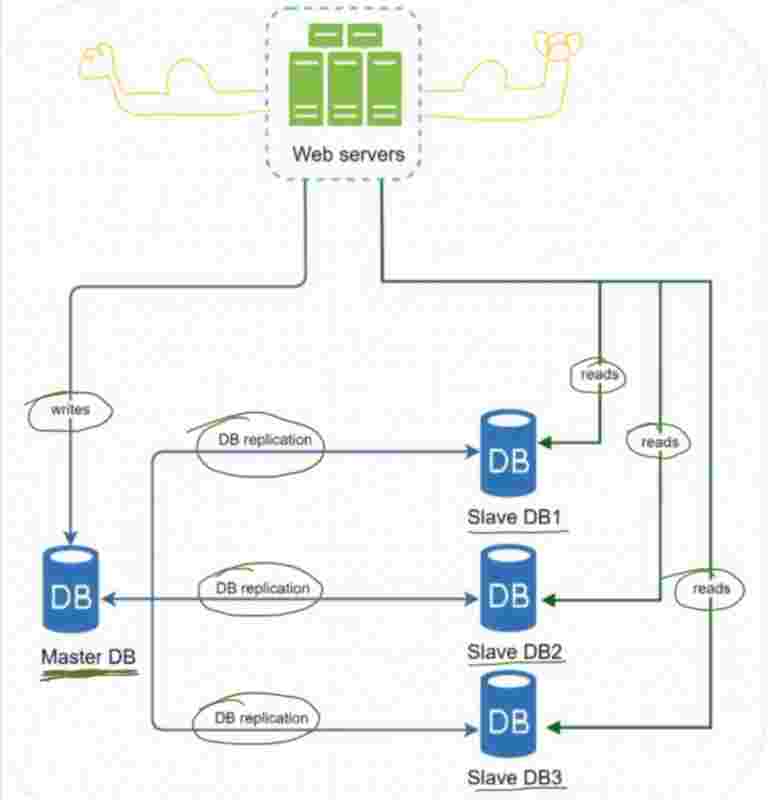
In most of the applications, the read/write ratio is always high, which means that the slaves >>> masters. The number of slaves required are generally more than the number of masters required.
So, what are the advantages of db replication?
1. Better perforamnce.
2. High availability.
3. Reliability.
So, this master slave model improves perforamnce because it allows multiple read/write requests to be executed in parallel.
We can also rely more on the database, even if your database gets offline, you can access database from another location easily.
So, even if your slave databases gets offline, we can transfer the read operations to master db.
And suppose our master db gets offline, then we'll just pick one slave db and do its promotion, that it'll be the new master db from now. And we'll get another slave db for it.
In real world production use, updating a slave db to a master db is really complicated setup, because there may be a case that data in slave may not be up to date, and there can be many other scenarios.
So, we handled server load balancing, database recovery through replication, and now, it's time to learn how to better the load/response time.
CACHING
Cache is like a temporary storage. It stores results of expensive responses, and frequently accessed data.
These server heavy responses that are frequently repeating can be stored in a local cache, so without even calculating anything, we'll just return the same responses we calculated beforehand without accessing the database unnecessarily.
By these ways, we can serve requests even more quickly.
Database would say, don't call me repeatedly when it's not necessary. Why putting all load on me?
Database says, take help of Cache.

So, before web server requests a response, it'll check whether cache has it or not, or cache has it then it'll be returned from it, else it'll then take result from database and store it in cache as well to be able to fetch from the cache next time the user asks for it.
The process of using cache is also known as read through cache.
Interacting with cache is simple, cache servers provide apis.
For example, suppose I have a key and I need the value of a key, so I'll just get that key and store it into the cache, with a time limit upto when it will be stored. So, next time user asks for it, if it is present in the cache, return from it.
Example code:
cache.set('my_key', 'hello', 3600 seconds);
cache.get('my_key');
Things to consider for using cache?
1. Cache is only to be used when data is read frequently and modified infrequently.
Because when modifying is done more often, then we also have to store it in the cache, which is not effective.
2. Expiration Policy:
Not too low - Data reload from database
Not too high - Stale data
There must be consistency as well between db & cache.
Multiple cache servers across different data centres to avoid SPOF (Single point of failure). That all servers pointing to only one cache will lead of issues.
When cache gets full; we have to implement various algorithms like LRU, LFU, FIFO to reuse the memory space. This is also known as Eviction Policy.
Least Recently Used - Removing the ones that were old.
Least Frequently Used - Removing the ones never used.
FIFO - Simple and sober queue, take that comes first.
CONTENT DELIVERY NETWORK (CDN)
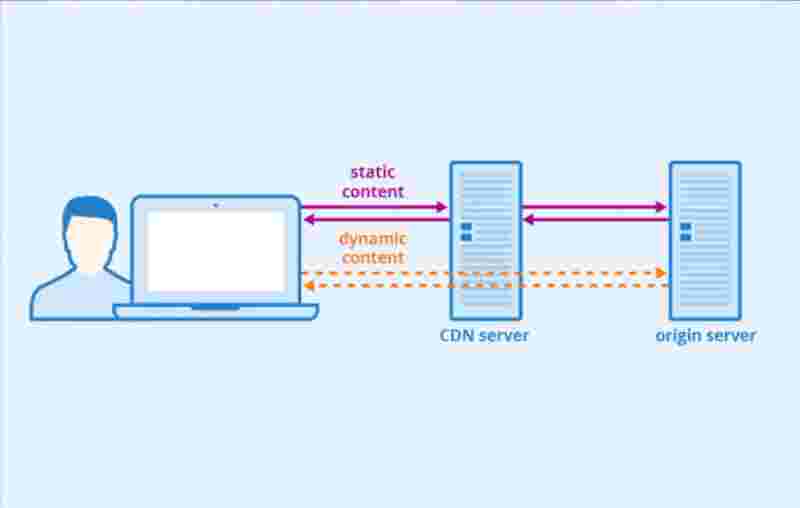
Before we learn about CDN, let us understand what type of content a website generally holds.
1. Static contents (Images, Videos, CSS, JS)
2. Dynamic contents (Changes according to user input)
Example: Website for sellign e-book (static content)
If we put the static content on the CDN, then our web server will have less load, and it'll load even faster.
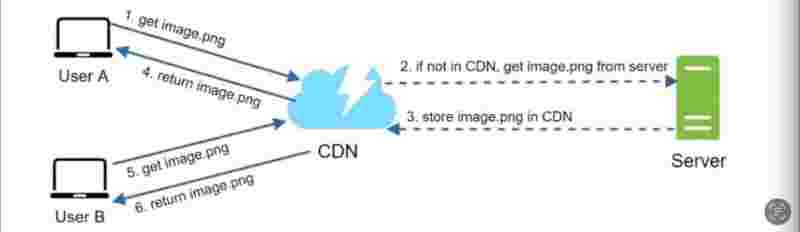
How CDN works (high-level view):
When user visits a website. CDN server that is closest to the user will provide the static content. If the CDN server is far away from you, then static content loading will take time.
Things to consider for using CDN:
Cost: Get rid of infrequently used contents.
Third party companies provide CDN and they charge you for using their CDN and sending the data. So, it's obvious that things not used very often should not be put in CDN.
Expiry time: Not too low, No too high.
Every CDN must be having an expiry time for your content which should be averaged as we did for our cache. If the expiry time is very low, then CDN will request again and again from the web server and load on web server will be high. And the expiry time should not be very high, because if data is kept for too long, then it is stale, and our bill will be generated unnecessarily, the same way as in cache.
CDN Fallback/Backup: We should keep this in mind, that if the CDN fails then we should be able to fetch from the web servers directly.
Invalidating files: CDN Vendors provide us with APIs to invalidate any file. The other thing can be versioning. For example, our image is stale, and we don't need it, as we have changed it to a new and better image.
So, we can do something like this,
Example: image.png?v=2
The CDN will understand that okay, the request is for a new version of the image file, then the old image file that was stale will be removed.
STATELESS AND STATEFUL WEB ARCH
Session Data/State: Data that represents user's session on web.
It is information related to the user. That we call session data. What can it help us with? It can help to identlify a user, and we can also authenticate the user. We also call this a state.
A web server holds the user information such as profile information, and session timeouts.
Suppose user A state info is stored in the web server 1, and user B state info is stored in the web server 2.
Now, if user A uses web server 2 because web server 1 somehow failed or was not responding, the authentication will fail and everything will break apart. Because web server 2 has no information for the user A. So, web server 2 will think it's an unauthentic user.
We do have a thing called sticky sessions in load balancers to force using a particular server only for a particular user, but that is an overhead. Even if it is not used, there is still an overhead to store the user's information in all servers leading to increased complexity and it is not a reliable solution.
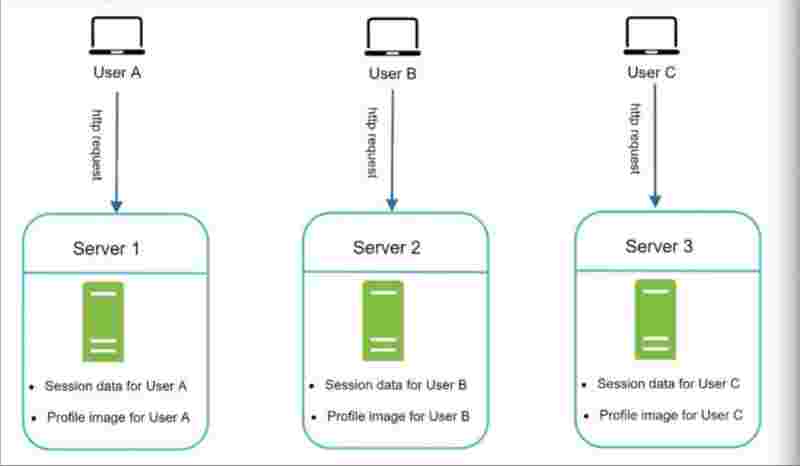
Suppose if we our servers get less load suddenly, and we want to remove a web server, to reduce the cost now, but that'll also delete the user sessions and information attached to that web server.
So, in those situations, we have to use a stateless architecture which'd help us.
First let us understand what is a stateful web?
A stateful web remembers client data, stores state information, and has overhead, not even simple.
A stateless web does not remembers client data, and does not stores any state information, therefore, it's simple and robust.
Now, suppose we use a shared storage, then the http requests can go to any web server without any need to track the state within the web server. It is reliable and scalable.
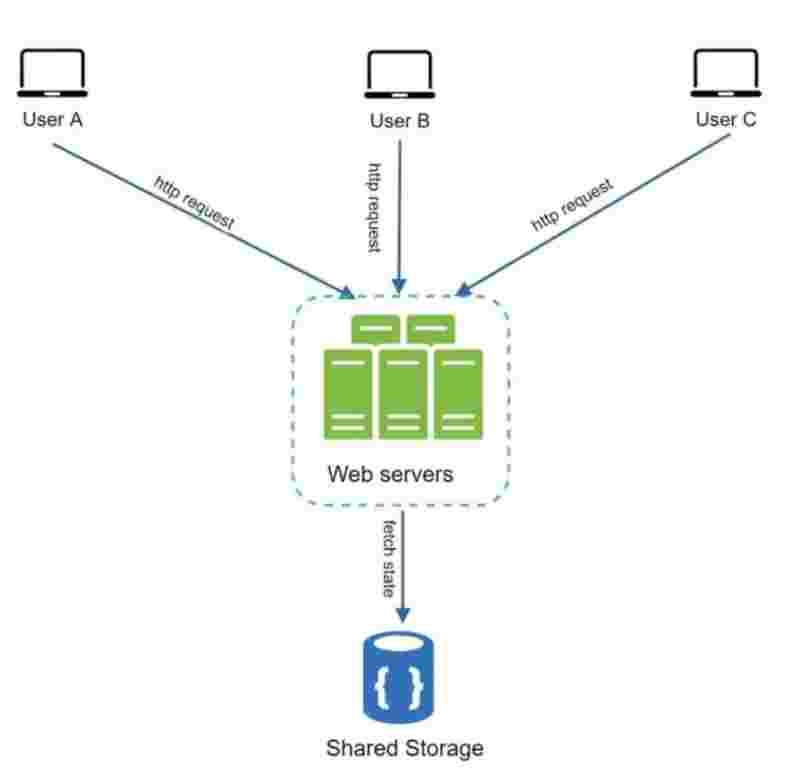
The state data has now been stored in a separate storage and is separate from the web server.
Let us recap and look at our service now.
It's just amazing. Reliable, scalable.
We have implemented;
1. Multiple servers
2. Load balancers
3. Master slave
4. Cache
5. CDN
6. Stateless
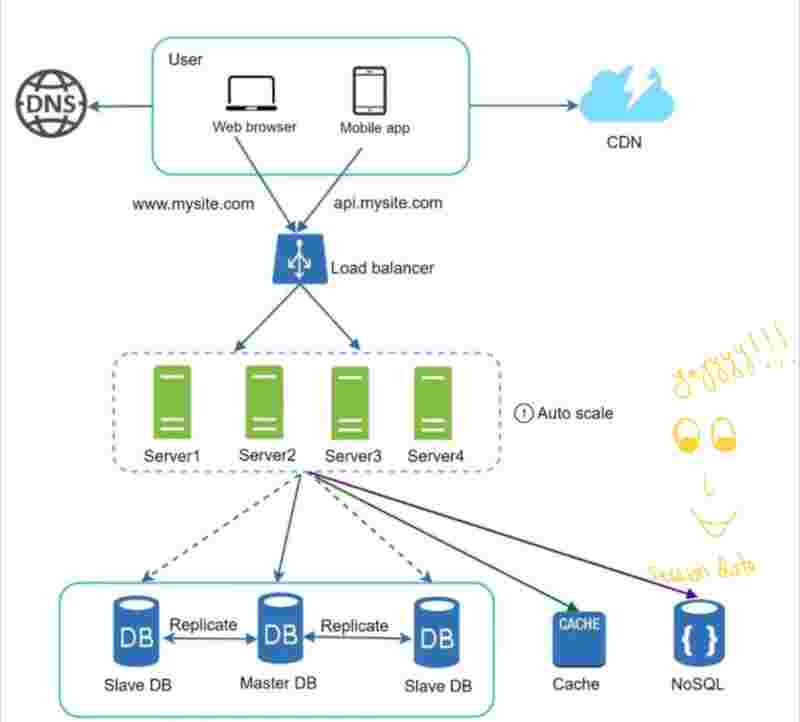
Since, we have separated the session informations in a separate database, we can easily autoscale.
DATA CENTERS
Suppose your website goes very popular, and their are lots of international users as well.
Now, to improve vailability and better user experience across wider "geographilcal" areas, we should support "Multiple data centres".
geoDNS: The routing is split between the closest data centers. Suppose we have two data centers in US, and clients from US are visiting our website. The traffic will actually be split across those two data centers.
What geoDNS does is, it takes the DNS (Domain Name), and, sends the ip address of the server based on the location of the user.
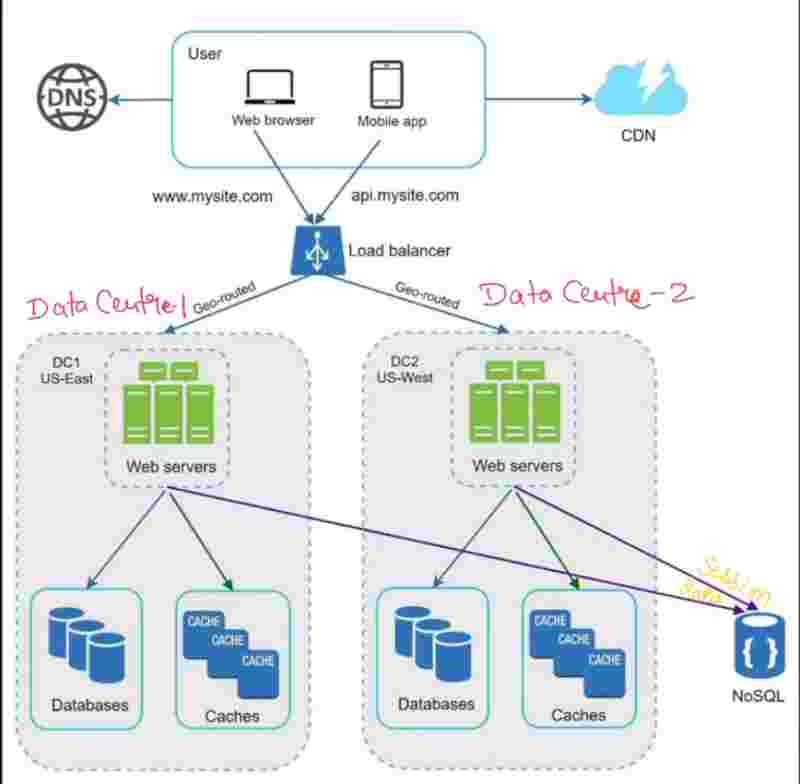
So, the US clients along the east side will get the server location of the east server, and the US clients near ot the west side esrver will get the server location of the west server, and this is how traffic is split.
Suppose our one data center has an outage like this, then we have to send the 100% traffic to data center one now, which is difficult and challenging.
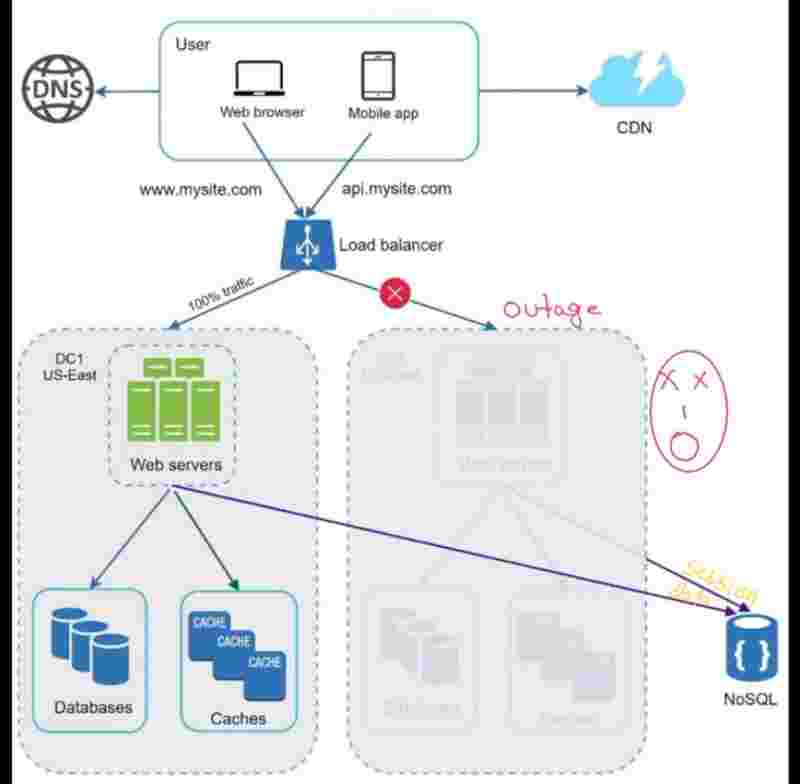
Technical Challenges to achieve multi-data center setup:
1. Traffic redirection: geoDNS does for us.
2. Data Synchronization: Replicate data across multiple data centers.
Suppose, we can redirect the traffic through geoDNS, but suppose we wanted the data that was exclusively present in the data server that got down. Now, even if the traffic got redirected, the data could not be fetched. So, we replicate data to solve this problem.
3. Test and deployment: Test your website/app at different locations to be sure that it is working perfectly.
MESSAGE QUEUE
Why do we need message queue?
What happens that in today's modern architecture, we break down the application into smaller independent chunks called decoupling. So, these decoupled chunks can be maintained, deployed, and updated separately and independently easily. It becomes very easy to develop and maintain.
Okay, we have done decoupling, but how do they communicate with each other? It is through message queues.
Message queues provide communiaction and co-ordination of them.
Message queues supports asynchronous communication.
The producer - consumer architecture. Producer sends commands to consumers which follows the orders of the producer.
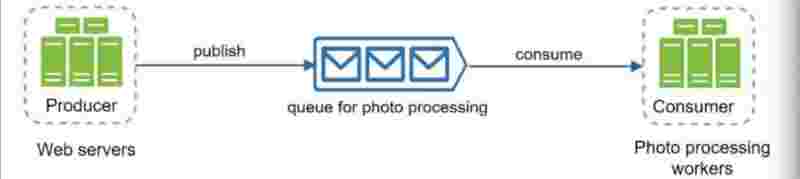
Producers are sending commands and they are being stored up in a queue, and the consumers who have subscribed to them will receive and get the commands from the queue and do their work.
Suppose that consumer is already busy in its task and not available now, then what producer will do is publish its message to queue and be free. Messages are stored in queue and whenever consumer is free, it'll consume the messages.
Some key points:
1. Producer can produce a message to queue even when consumer is unavailable.
2. Consumer can read message form queue even when producer is unavailable.
Producer and consumer are independent, you can work on both separately, and can scale them up separately.
This is what we call asynchronous communication.
There is no synchronization between producer and consumer. Producer can send anytime, and consumer can consumer anyday, depending on whether they are free or not.
Suppose we take the example of a photoshop, where we request the photo editor to process our photos. Now, the consumer, the photo editor may already be busy with processing other photos. So, what producer is doing is just sending it's request to the message queue, and now producer is free. And the consumer can process the photots whenever it gets free.
So, both producer and consumer are always independent of each other. Suppose, we have a lot of photos coming up for processing, so what'll do is increase the consumers. We scaled up consumers (workers) only.
We can independently scale up and down consumers without even being dependent on the producers.
1. Independent
2. Scaled Independently
3. If queue size is large, add more consumers / workers
4. If queue is empty mostly reduce consumers / workers
Being independent, debugging is much easier and reliable.
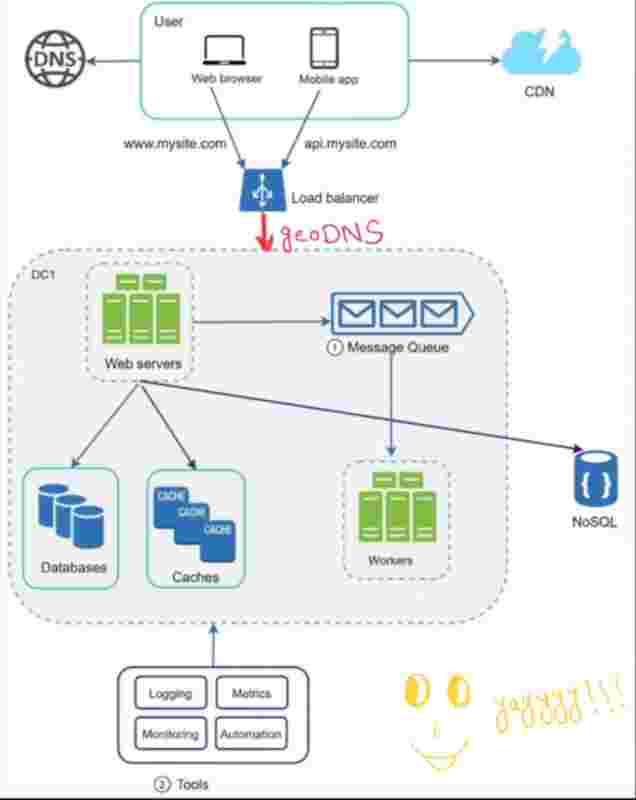
LOGGING, METRICS, AUTOMATION
Logging: Monitoring error logs, per server level, centralized logging. Example: new relic
When our website is small, and there are few servers, then it is not a necessity to log the metrics, but supose when the website is busy and there is a good amount of traffic, a good business model, then it is essential to log metrics.
Suppose there is a error in your service, then you should be able to monitor it right. You should be logging it somewhere, only then you will be able to deliver efficient products. You can log at servier level as well, from which service has error came. You can even lock servers where errors are coming up. For example, new relic. In which all logs, of the servers and the services are seen at one place easily. So, when there is any issue then we're able to find where one can debug. Logging is very helpful in debugging and finding the erro .
Metrics: Gain bussiness insights. Aware of health of our service. Host level metrics: CPU, Memory etc.
Different types of metrics collection can benefit us a lot, how? It gives you bussiness insiders, and gets to know about the service health. For example, see it's types;
1. Host level metrics: the host where your service is being run, how much is its CPU, and how much is its memory now, so you have to take care of these things very carefully. For example, CPU got increased abruptly, then alerts will come up, and there can be problems due to it, so all these are in one place. So, we need a dashboard kind of thing where we could just see everything all at once, so that you can check your usage. For example, I use Grafana.
2. Aggregated level metrics: You can see the metrics of the total performance of your database and the total performance of your cache etc.
3. Key business metrics: Daily active users, and how much revenue is your service earning.
AUTOMATION
So, when your system gets complex, then we have to use automation tools which can make our deployment very easy. The code changes that we have made, submitted, their verificaiton, can be done automatically, this will improve our productivity, our time will be saved as well. If these tools are doing something like this for us, then now we will reduce the load on it.
Containers integration is very important, so you'll see, in our github, we can see whether there are any issues in our changes or not. The second thing, is automating bills, test deployment, and all these can also be done automatically. Suppose, you have made your changes, and you have to build the service, so in Jenkins, you can easily automate it, everything from testing to deployment, so automating is very very important for a service, now a service is, big and complex.
DATABASE SCALING, SHARDING AND JUSTIN BIEBER PROBLEM
When data grows, then database overloads, so we have to scale our database servers.
Database Scaling:
1. Vertical Scaling
2. Horizontal Scaling (Sharding)
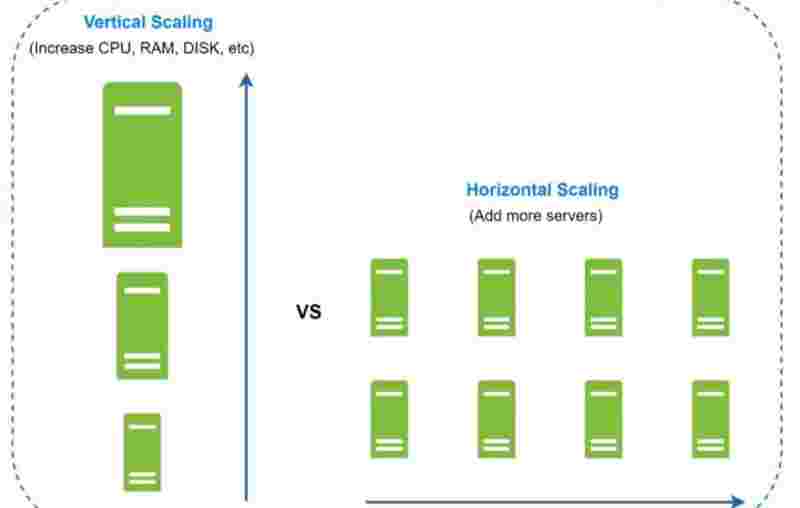
In Vertical Scaling, we are increasing more power (cpu, ram, disk). According to RDS (Amazon Relational DB service), we can take upto 24 tb of ram. For example, in 2013, stackoverflow was handling 10 million unique visitors everyday with only one master db. If that master db got failed, then everything would be gone for stackoverflow, but it presisted somehow.
The drawbacks of vertical scaling are that, hardware limitations are real, and there can be a single point of failure, and it'll be costly as well.
In horizontal sacling, adding more servers is also known as sharding, what we do is rather than having a large database, we can have shards, that means, smaller and easily manageable components of the large db, to easily manage them. In which shard component will our data go, for that, we use a hash function, in which we use a hash key, known as sharding key. The sharding key is something that has to be choosen very carefully, so that the data is evenly distrubited among these shards. We can even use multipe database columns to have our sharding key. It should be choosen very wisely.
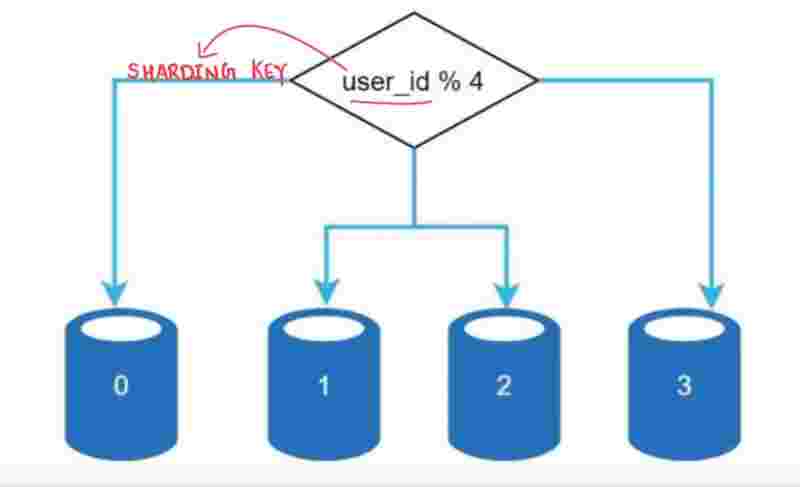
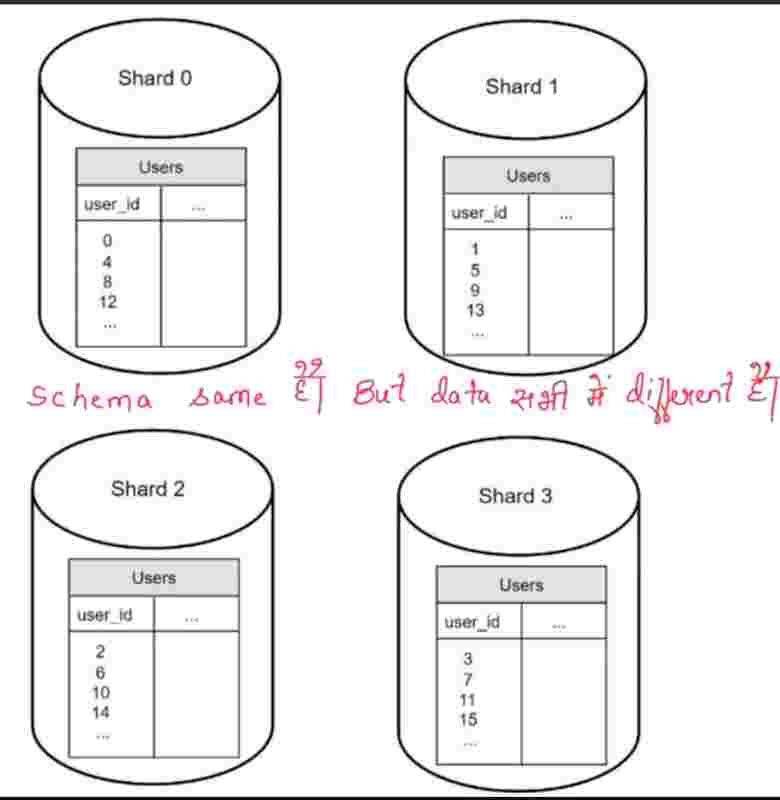
Drawbacks of sharding;
1. Resharding: when a shard has reached a stage when it can no longer hold more. . then shard exhaustion due to uneven distribution. It will require, updating sharding function, then moving data around. It will be a overhead to do everything all again just because of uneven distribution.
2. Celebrity problem (Hotspot key problem): Excessive access to a particular shard cause shard overload. Suppose in shard 1, we have justin bieber, eminem, and lady gaga, and in shard 2, we have no celebrity, just because shard 1 has popular people, maximum read requests will be towards shard 1, and shard 1 will be overloaded. So, what can we do to fix it? We can assign each shard for each celebrity, and we can balance the load for each shard evenly. This is a real story, that whenever justin bieber uploads a photo on instagram, then their apps goes very very slow. Because of overload of like requests on one post, the shard is overloaded. They implemented caching technique to fix it, but even then, cache cannot take the load. Finally, when facebook admired instagram, they fixed the problem, the like counter is stored in a separate database cell, and then only it got solved.
3. Sharding makes it difficult to perform JOIN operations, common fixes are denormalize the database so that queries can be done in a single table.
SUMMARY:
1. Keep web tier stateless.
2. Host static assets in CDN.
3. Support multiple data centers.
4. Build redundancy at every tier.
5. Cache data as much as you can.
6. Scale your data tier by sharding.
7. Split tiers into individual services.
8. Montior your system and use automation tools.
💬 Comments will load when you scroll here